

Curious about the use of generative AI in the microstock industry? In this blogpost, we’ll take a look at the relationship between this cutting-edge technology, agencies, and contributors. If you think that artists eventually will be replaced, you are right! And wrong. We will explore what realistically can happen and what to do about that. The best part is that you’ll learn how to use generative AI as an amazing tool to boost your creativity. So, let’s get started and see where this AI adventure takes us!
Introduction to Generative AI
Generative AI for images is an exciting and rapidly-evolving technology that is changing the way we interact with and create visual content. At its core, this technology uses statistical algorithms to learn from existing images and then generate new, unique visuals on its own. This technology has many practical applications and has already begun to transform various industries. For example, in the world of fashion, generative AI can create new clothing designs and patterns, or even entire fashion lines. In the entertainment industry, it can be used to develop unique animations and backgrounds for video games. In the world of microstock, it is used both by agencies and contributors to create content customers want, either by generating it from scratch or by modifying the existing one.
How does Generative AI work
One of the most popular techniques behind generative AI for images is called a Generative Adversarial Network, or GAN for short. A GAN consists of two parts: a generator and a discriminator. The generator is like a creative artist, trying to come up with new, convincing images, while the discriminator is like an art critic, judging whether the generated images are believable or not. The two parts work together, continually improving each other, until the generator can produce images that are nearly indistinguishable from real ones.
Before the AI model can learn to generate content, it needs to understand and recognize patterns in the type of content it will create. To do this requires a large dataset of examples, and large here means 250 million images and more. Each of these images has to have meaningful labels (which are just “keywords” from microstock jargon), helping the AI model to identify patterns and features. During training, the model is exposed to the labeled examples, learning to recognize patterns and relationships within the data. The model goes through the dataset multiple times, refining its understanding and improving its performance. Think of it like an artist practicing their craft, getting better with each attempt. The amount of compute resource needed for such training is insane and is comparable with electricity used by 100-200 households per year.
Can AI be creative
While generative AI has shown promise in producing mind-blowing images, one can’t help but wonder if these creations can truly be considered creative. Not that someone cares in general, but this is the aspect that feels threatening to us, humans. Creativity, by definition, involves generating original ideas and breaking away from established patterns. Furthermore, creativity is often the result of human experiences, emotions, and cultural contexts – aspects that are hopefully challenging for AI models to grasp. Not to mention that the AI model is trained on a limited dataset, thus the extent of the “genuine” creativity is constrained by definition.

Looking at it from this side - no, they are not creative. They lack the depth and complexities that arise from human expression and imagination. However, they can and do produce unexpected results. Playing with this technology you will say “wow” many more times than you anticipate. And while it cannot match human creativity, it can boost one, mixing and matching things and styles that you, perhaps, did not consider before. In the end, I’d say the question is not what “creativity” really means in the context of generative AI, but if it is useful for you.
Potential for microstock platforms
It’s no secret that lately major marketplaces of every kind are shifting to produce content themselves. Think Netflix investing heavily into its shows, Apple creating shameless clones of the most successful applications from the AppStore or … microstock platforms offering a buy-out for cherry-picked accounts. Now with generative AI developments, agencies will have another tool in their arsenal.
An obvious benefit of using generative AI is the ability to generate images at a fraction of the time and cost compared with traditional photography (if you have a pre-trained model). Also, AI-generated images can be tailored to the specific needs of individual clients, offering a more personalized service. This could lead to increased customer satisfaction and, ultimately, higher revenues for the platforms. Additionally, generative AI can be used to create images that fill gaps in the existing inventory, ensuring that platforms can cater to niche markets or emerging trends more effectively.
Needless to say, agencies are more than excited about these possibilities. So much so, that they are now creating these very models in the first place. For example, Adobe released a Firefly model, not only to be used online but also rumored to be available in Photoshop. And Shutterstock followed suit with its own image generator.
When Generative AI will replace microstock contributors
To put it lightly, the rise of generative AI for images seems to present a “challenge” for contributors (particularly those at the “low end”). The surge in AI-generated content will create a more competitive landscape, both raising a bar for your content to be noticed and decreasing the price customers pay on average.
However, at the time of the writing of this blogpost, even “best of the best” models still occasionally add or take a finger in the picture, make one eye look sideways, or blur some foreground. It’s reasonable to expect that, in the close future, they will become better and will fix at least some of these problems. Nevertheless, if you would spend some time playing with technology, you can notice that AI-generated images look quite similar. Sure, they can mix and match different things, but with time you start noticing patterns and even start noticing AI-generated content online. This means that customers who are looking for authentic content, will likely not accept this quality.

Example of 'outpainting' by a generative AI
With that said, even now AI models can generate a good amount of incredible illustrations that supposedly will cover the needs of a certain amount of customers. But it’s unreasonable to expect that soon these models will generate high-quality vector files, coherent videos, or top-notch photography. Yes, ChatGPT-4 can write some HTML code so you can expect it to learn to generate vector files too (e.g. SVG vectors are similar to HTML code). However, the model can only generate small pieces correctly and even such you need to adapt it for integration into a larger one. Go check out the recent Adobe interview of Yuri Arcurs and learn of how insanely hard and professional they are working to produce microstock content. Rest assured, generative AI will not get to that level any time soon.
Another area, unpractical for generative AI you might think of, is the editorial photography and videography. AI could be used already today even to generate deep-fake videos, but they look .. fake. Unique photography from new events from real life will be as needed for news outlets around the world as it always was.
Even if you assume all of the above is false and AI will replace all of us soon, who will generate new content for the training of such AI, to begin with? Marketers today would not opt to use AI models trained on data from the 90s. While using the model is comparatively cheap (only if you compare it with hiring an artist), training the model is extremely expensive and requires a lot of data (in addition to a lot of resources). Shutterstock has “only” over 430 million images as of December 2022, while DALL-E 2 used 600 million for training. Therefore there will always be a need for human-created content and my bet is that, in the future, the value of human-created things will only raise.
And, what is maybe the main point of this whole blogpost, there are also opportunities for contributors to adapt and thrive in this new landscape. By embracing generative AI as a tool, contributors can enhance their creative process by generating novel ideas, getting unblocked, or producing work faster than was possible before.
Generative AI tools you can use today
Check out an overview of which tools allow you to legally sell on microstocks.
DALL-E
DALL-E is a system developed by OpenAI that has quite extensive capabilities for image generation. You can generate images based on prompts, edit generated or uploaded images (editing means adding or removing parts), organize your generations into collections, etc. It performs well both in the photorealistic and artistic domains.
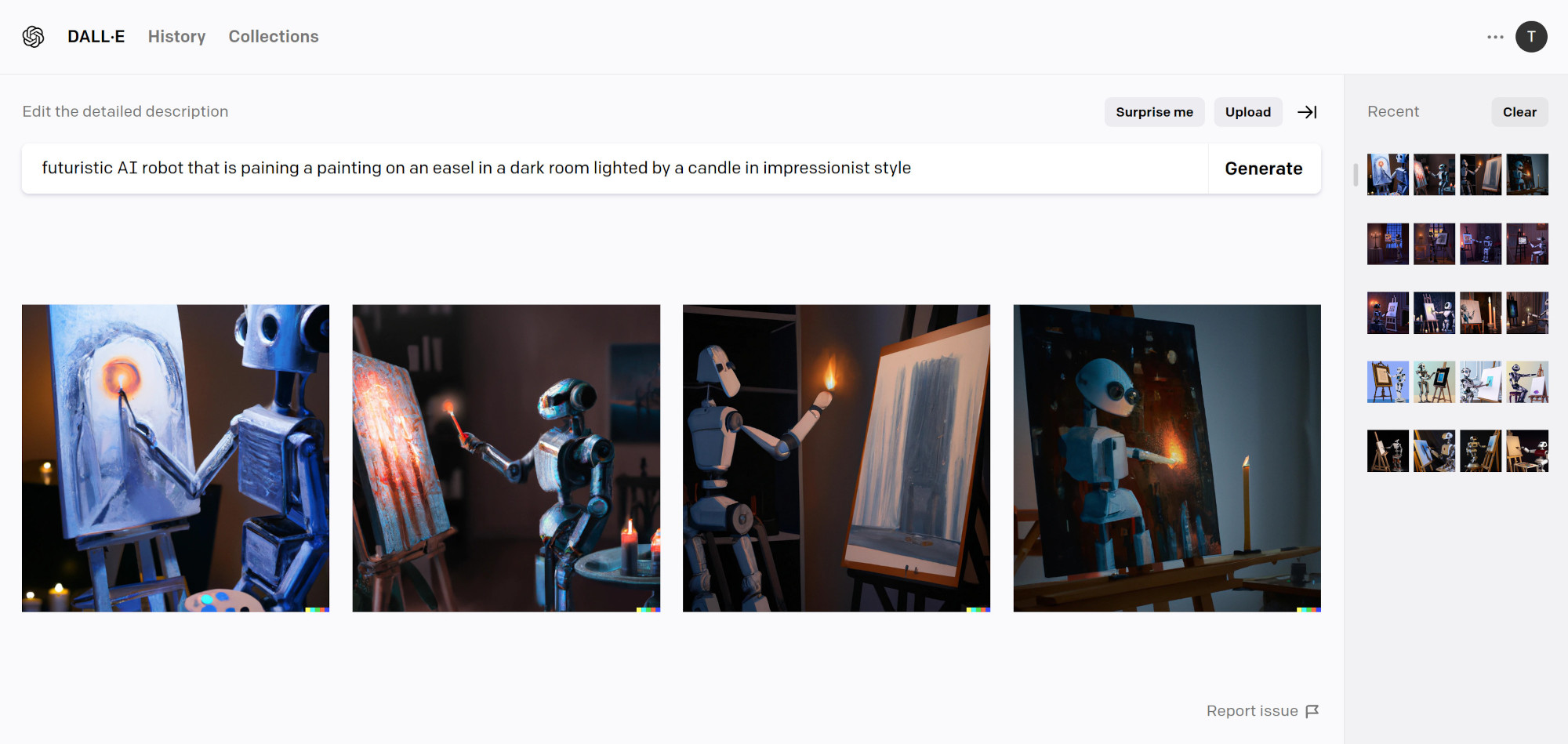
Each generation produces 4 options you can choose from
In the web portal not only you can generate images based on Text prompts but also edit generations, generate additional parts of the image, or upload Sketches or Semantic maps. This is useful as default generations are 1024x1024 and if you need a 3:2 image, you need to generate sides additionally (also known as “outpainting”). Check out their image editor guide.
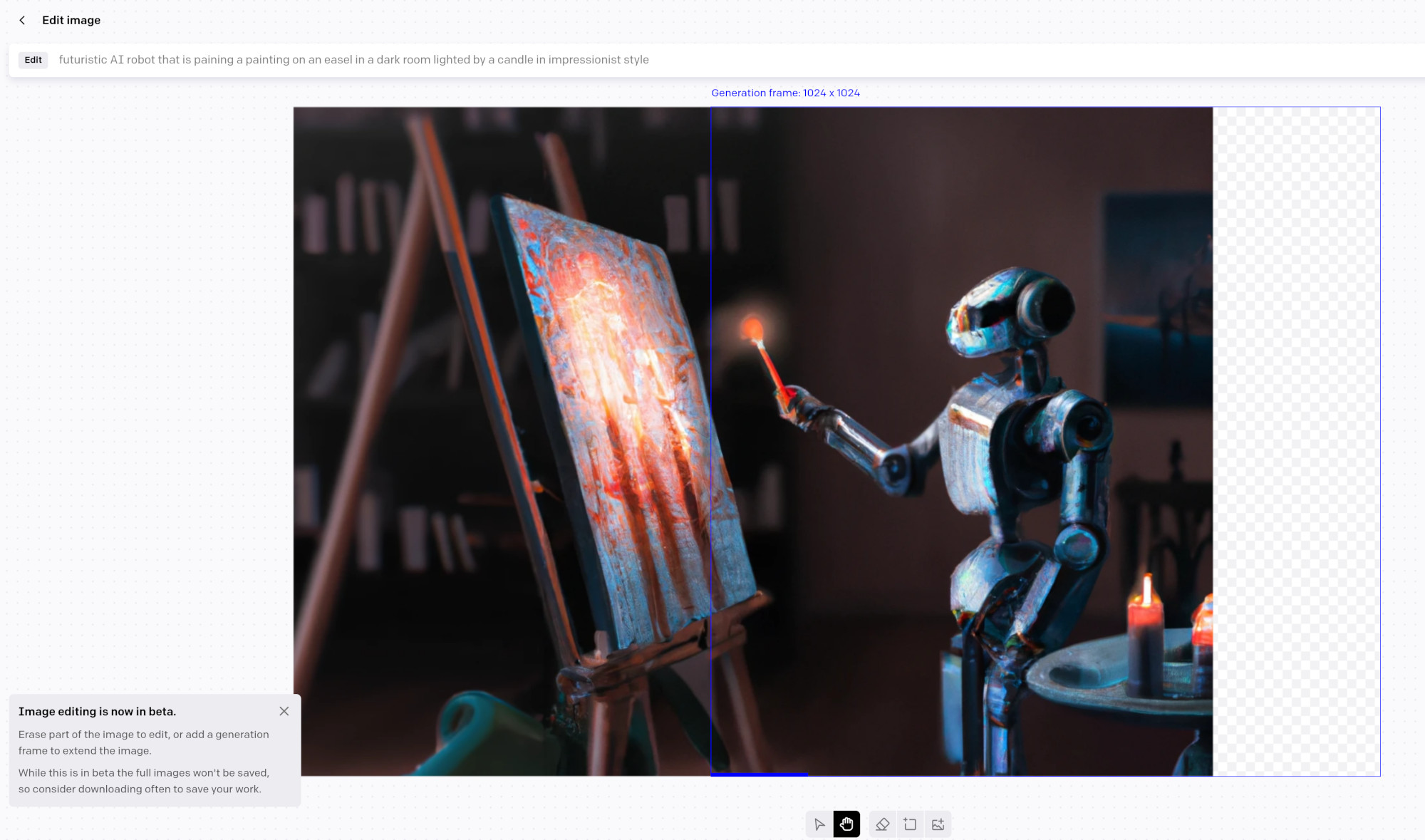
Outpainting right part of the cover image in DALL-E image editor
Another kind of image editing DALL-E can do is to “inpaint” missing parts of the image:
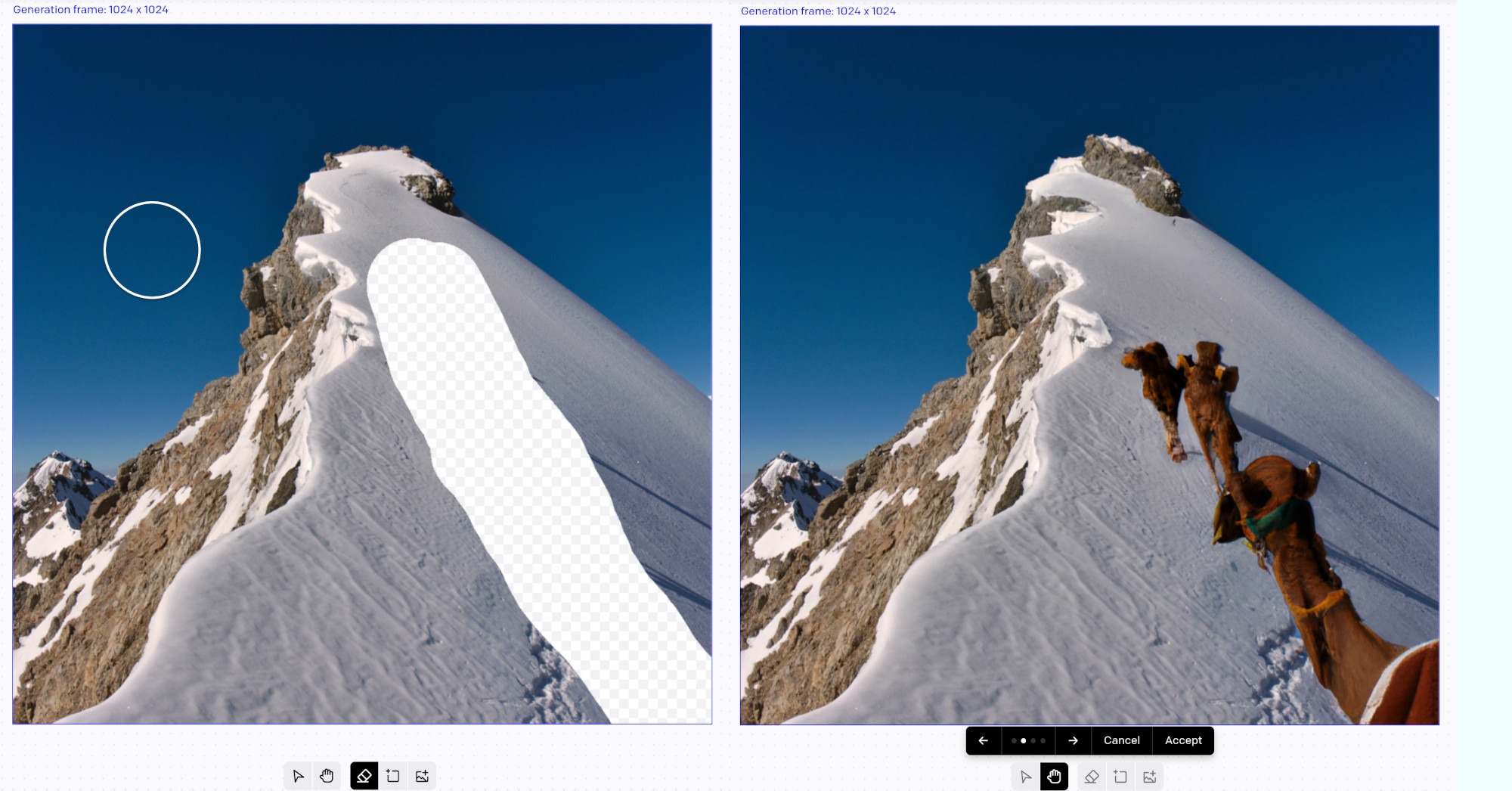
Inpainting missing part of the image with camels
You can see all your generations and their prompts in History. Additionally, you can save generations to various collections which is very helpful in the long run.
Pricing
Pro tip: if you want to only evaluate the system using free credits, do it when there’s night in the US timezones as the most load comes from it.
Each generation costs 1 credit and each month you get free 15 credits (that do not accumulate). You can always purchase more credits: 115 currently costs $15, effectively paying $0.13 per 1 generation. In case you are only using free credits and the system is overloaded, you might need to wait for your turn to generate.
API
Note that DALL-E is also available via API too and many other companies like Microsoft, Jasper AI and others are actually using DALL-E in partnership with OpenAI, instead of developing their own tool.
Midjourney
Midjourney is an independent entity that works on AI models with the same name. With the lack of a web platform they are using Discord to operate. Although the Midjourney model also has photorealistic data, it performs best on artistic/illustratory images.
To register with them, visit Midjourney website and click “Join the beta” button or click the link to Discord invite page directly. You can create a Discord account before accepting an invite if you don’t have one. After you will accept the invite, you will be able to start generating images in one of the newbie’s rooms.
'Newbie' rooms
Enter one of the chats and type /imagine, space ( ), and then your prompt. Note that all the generated images are publicly visible. If you want to generate private images, you need to subscribe to a higher-paying tier (starting from $60/month at the time of the publication).
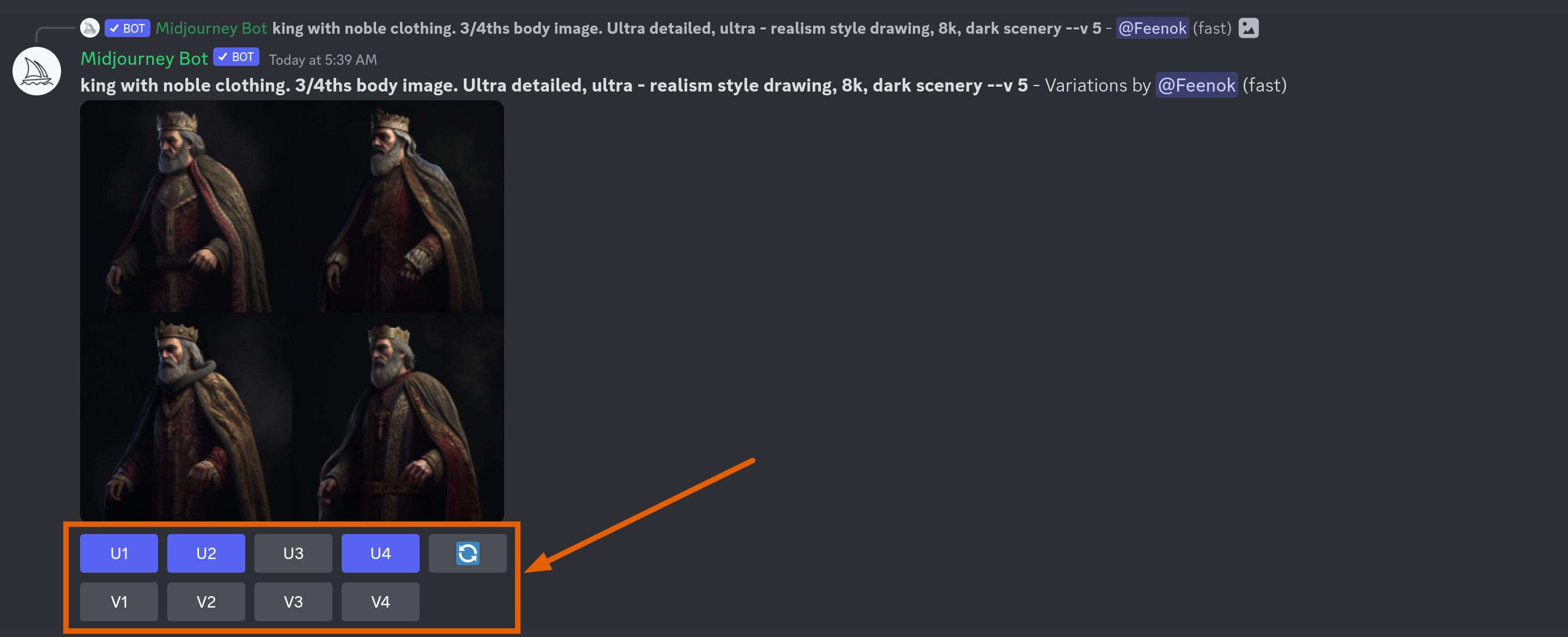
Editing options for each generation
After each generation, you are able to upscale each of the 4 generations ("U" button) and choose the variation ("V" button) and the bot will reply with the result below. Midjourney allows you to specify a lot of options for generation such as sides ratio (e.g. 3:2), quality of the generation, style, and many other things. Check out their quick start guide to get up to speed.
Midjourney does not provide you with an easy way to find or categorize your generations. Most probably the best way to do it is manually on your computer once you downloaded them.
Pricing
Sensible image generation starts at $10/month (or $8, if you pay yearly) that gives you approximately 200 quality images per month (the exact number depends on a prompt and options). You can subscribe by using /subscribe command in the Discord chat. Midjourney has stopped providing free trials some time ago after seeing an influx of users.
Stable Diffusion
Stable Diffusion is an open model created using resources from the company Stability AI that you can run on your own hardware. It’s trained on 512x512px images, but it can be used just like DALL-E or Midjourney. There are many desktop applications that wrap Stable Diffusion and give you a simple UI to produce images. They take care of model downloading and environment setup. What is common about them is that you have more toggles to push than with DALL-E, but also you need to know what you’re doing.
DiffusionBee
For macOS, here’s the DiffusionBee app that runs on both Intel and M1/2 Macs. DiffusionBee allows you to outpaint and inpaint as well as use Image prompts for a generation. It also allows you to upscale the generated art twice the size. One useful configuration it has is “creativity” - how much AI is allowed to diverge from your prompt.
Generation using Stable Diffusion model in the DiffusionBee app
There are quite a few desktop applications you can use (e.g. another example for macOS is Gauss). These applications will work even if you don’t have a decent video card, but you should expect slow generation times. On the computer used for the screenshot above, the generation of 1 image took about 1 minute on a GPU, which is slightly longer than DALL-E or Midjourney took for 4 images, but not too bad.
Note that for local models to work well and not drive you nuts, it’s better to use a relatively decent video card as CPU will take up to 10 minutes per image.
Easy Diffusion
Another worthy mention is the Easy Diffusion - a cross-platform option that works on Linux, Windows, and macOS. During installation, it will download models and start a web interface where you can run your prompts. This is only slightly more technical, but very powerful platform you can host on your computer. Note that it takes some time the first time you run it (both app and generation) to download and set up the model.
Easy Diffusion web interface
Microsoft Designer
Microsoft Designer (or Bing image creator DALL-E 2 in disguise) is a web application from Microsoft. It is a slightly different beast, but nevertheless interesting for our purposes. Instead of straight away generating your AI art, the primary goal of the app is to generate the final product, maybe using generative AI on the way. For example, if actually I wanted to generate a header image for this blogpost in Microsoft Designer I’d use the prompt "Cover image for the blogpost about Generative AI" instead of "robot painting on an easel in a dark room". This is also what Jasper AI is aiming for.
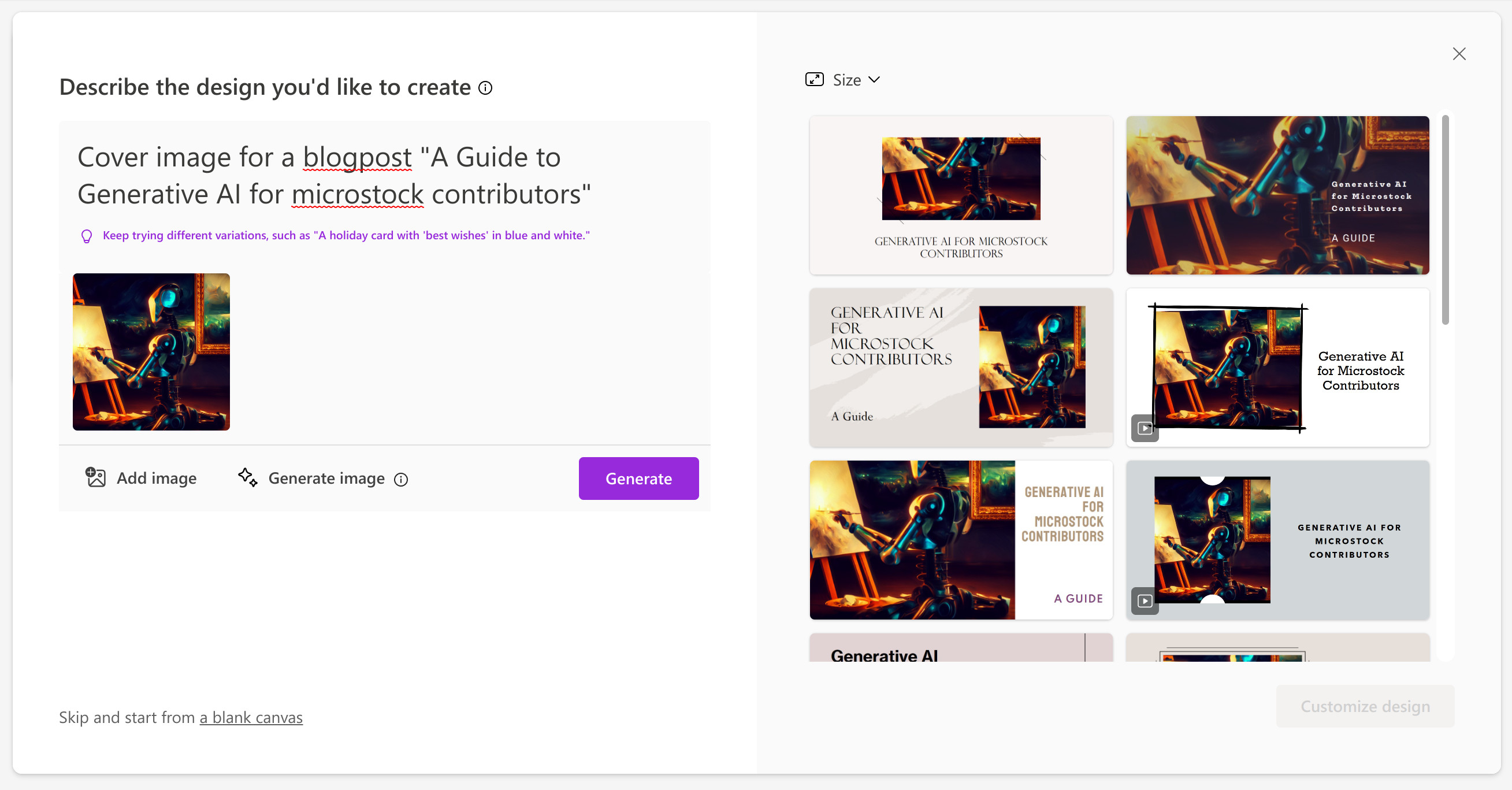
Microsoft Designer attempts to create 'a finished product'
However, there’s a way to generate AI images there too. Under the prompt, there’s a link “Generate image” that takes us to an already familiar DALL-E prompt.
Finding DALL-E 2 prompt in Microsoft Designer
You can only create AI art, but not edit it. However, there’s nothing that prevents you to generate part of the image here and continue with other tools. In addition, during the beta program, it’s free.
Other services
There are way too many image-generation services to count them all. Dream AI, Jasper AI and about 40 more “XYZ AI” services you can find in the DALL-E alternatives page. They are growing like mushrooms after the rain. You can try them out if you want, but they are mostly very similar, which is good for us, consumers, and bad for them.
How to use the tools: prompt engineering
Generative AI models for images rely on various types of prompts to guide the creation of desired outputs. These prompts serve as instructions or cues for the AI to generate images that align with the user’s intent. Here are the most popular ones.
Text prompts
Text prompts are simple written descriptions that specify the subject, theme, or elements of the desired image. For example, a text prompt like "sunset on a beach with palm trees" gives the AI model a clear idea of the scene it needs to generate. Text prompts can be more or less detailed, depending on the level of control the user wants over the generated image.
These will be the kind of prompts you would use most often, at least in the beginning. Therefore it will pay off to learn to use them well. One great resource that can help you is the prompt guide from OpenArt. Another one - you can learn by copying from prompts in the Midjourney’s discord or AI template libraries like OpenArt presets or ArtHub library. Lastly, you can check out curated art galleries, such as ArtHub or Lexica.
Image prompts
In some cases, users may provide an existing image as a starting point for the generative AI model. The model can then create a new image based on the input image’s style, color palette, or composition. This approach is particularly useful when users want the generated image to have a specific aesthetic or visual quality similar to the provided example.
This is what happens when you press “Make variations” in the image generation services: the image you’ve selected is taken as a prompt. This is also how inpainting and outpainting work: you don’t need to provide the full image to start from.
Sketches or outlines

Providing a rough sketch or outline as a prompt allows the AI model to generate an image based on the provided structure. Users can draw basic shapes, lines, or contours to represent the desired layout or composition, and the AI model will fill in the details to create a complete image. This approach offers users more control over the generated image’s composition and spatial arrangement. You can check examples on crappydrawings.io.
Style prompts

Style prompts refer to instructions that define a specific artistic style, technique, or genre for the generated image. These prompts can include the name of an art movement (e.g. "Impressionism"), a famous artist (e.g. "Vincent van Gogh") like on the picture, or a particular visual style (e.g. "watercolor"). The AI model will then generate an image that adheres to the characteristics and aesthetics associated with the given style.
Semantic maps

Some advanced generative AI models can use semantic maps as prompts. A semantic map is a spatial representation that defines different regions or segments of an image and associates them with specific labels or concepts (e.g., sky, grass, water). By providing a semantic map as a prompt, users can guide the AI model in generating an image with specific elements or objects placed in designated areas.
Selling AI-generated content
Legal issues and push-back from artists
Selling AI-generated content is a controversial topic in general. All agencies clearly state that you need to own all rights for the content you produce. In the end, that’s why you’re Photoshopping brand names out and Yuri Arcurs produces his own clothing line. As to the AI-generated content, this is taken to the extreme as hypothetically you are creating a derivative work from multiple artists at the same time.
Accordingly to the decision of US Copyright Office, “works of authorship” are limited to the creations of humans, so you cannot copyright AI-generated content (case link). So it’s expected to have some legal turmoil in this area in the nearby future.
Not to mention that artworks of vast majority of artists are taken without their consent which causes a backlash. This holds even for big players, like Getty Images, whose images were scraped without any consent by Stability AI and who is now being sued, as announced in the Getty newsroom.
One funny thing is that copyright law is different for music industry and even Stability AI has music generator that only uses royalty-free music, citing the reason "Because diffusion models are prone to memorization and overfitting, releasing a model trained on copyrighted data could potentially result in legal issues.". However for some reason industry treats visual artists differently.
So legally this is a “gray area” at the very least. But it does not prevent some agencies from accepting AI content.
Who is selling AI-generated artworks
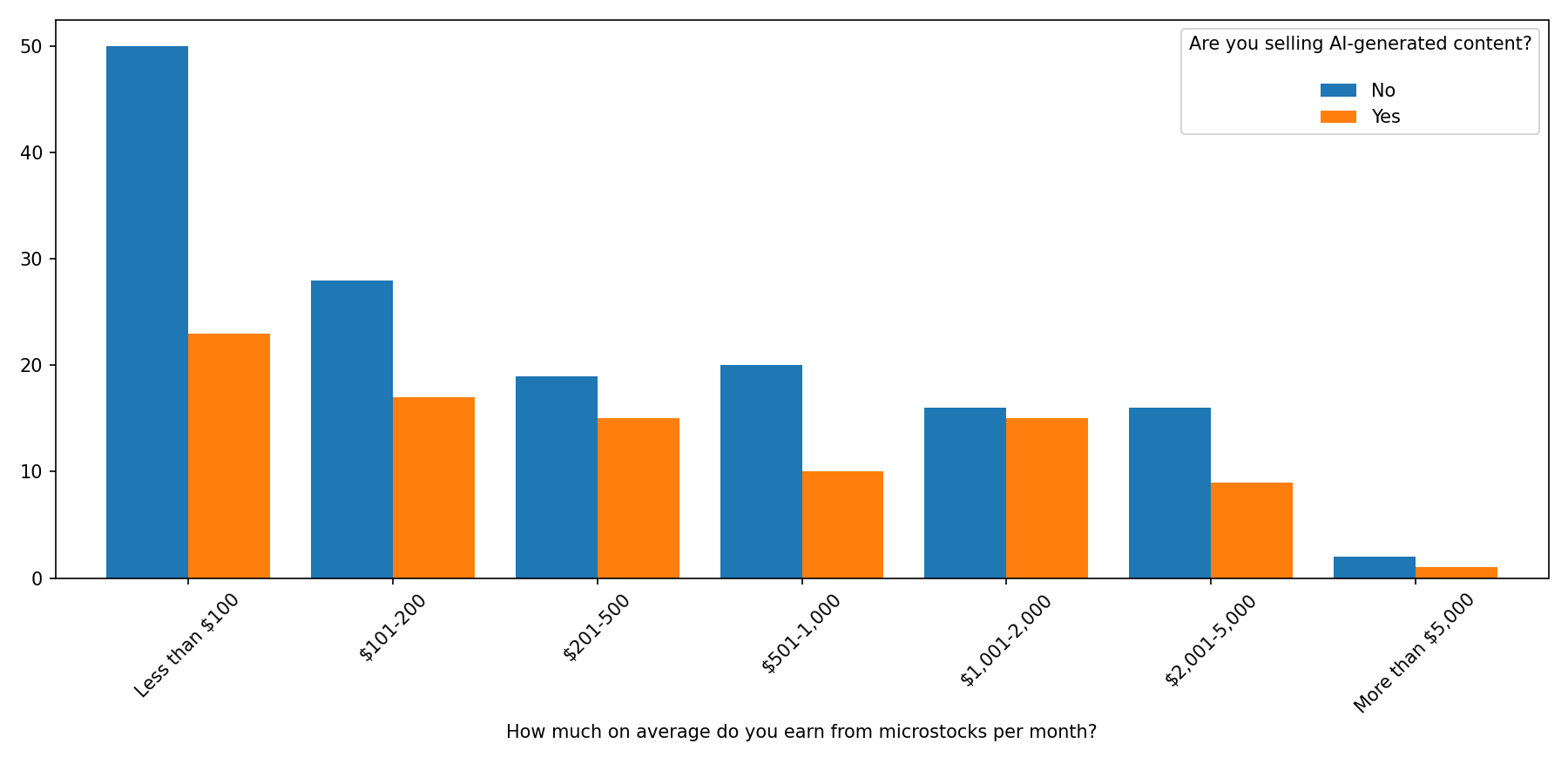
Contributors of all earnings tiers are actually selling AI-content, accordingly to our 2024 microstock survey. The only exception are lower-earning tiers that sell less of AI-content than their higher-earning peers.
Agencies that accept AI-generated content
Agencies here split into 2 camps: some are banning AI-generated content (obviously while generating it themselves) and others accept it. Let’s look briefly at the most prominent ones:
| Agency | Accepts AI content | Has AI generator |
|---|---|---|
| Shutterstock | No (policy) | Yes |
| Adobe Stock | Yes (policy) | Yes |
| Getty Images | No | Yes |
| Pond5 | No (policy) | No (but Shutterstock has) |
| Depositphotos | No (policy) | No |
| Dreamstime | Yes (announcement) | No |
| Alamy | No (announcement) | No |
| Creative Market | Yes (sort of) | No |
| 123rf | Yes (announcement) | No |
| Canva | No | Yes (sort of) |
| Vecteezy | Yes (policy) | No |
| Panthermedia | Yes (announcement) | No |
Pond5 does not have its own AI generator, but its parent company, Shutterstock, has. So they will unlikely work on a separate one.
Note that Creative Market does not have an official policy as it is a marketplace for marketplaces. Therefore you’re running your own “shop” where you sell what you want, but you also need to have the full copyright for the artwork.
Canva released its image generator, but it has limited capabilities for the purpose of the Canva functionality and not as a standalone tool.
Requirements for keywording and uploading
One obvious requirement is not mentioned: there’s no point to submit content with people who have 6 fingers instead of 5 or distorted faces. Remember that all previous microstock content quality requirements are still in place.
First and foremost is that you need to own all rights for the content you produce. Usually, this means that “free credits” in DALL-E, Midjourney, and others don’t work as their terms of service state that you own rights to the generated images if you pay them. Unless, of course, you’re running your version of Stable Diffusion locally.
Secondly, there are metadata requirements. For example, Adobe states that you can only submit such content as “illustrations”, even if it’s generated as a photo. Then you need to have the keywords generative AI, generative, and AI added to the list of keywords and, lastly, a description should end with "Generative AI". Dreamstime also states that you can only submit such content to the category Clip Art / AI Generated and that you must mark your content as generated by AI in the description. 123rf demands to add "AI Generated" to the Description and Keywords and use "Ai Generated Images" category only.
And third, agencies don’t want to tag or identify AI content with anything real, starting with people. People with visible/identifiable faces are not allowed as this would have required a model release, which is quite tricky in the current context. The same goes for property releases. Additionally, you cannot add keywords that resemble names of real properties, people, or places.
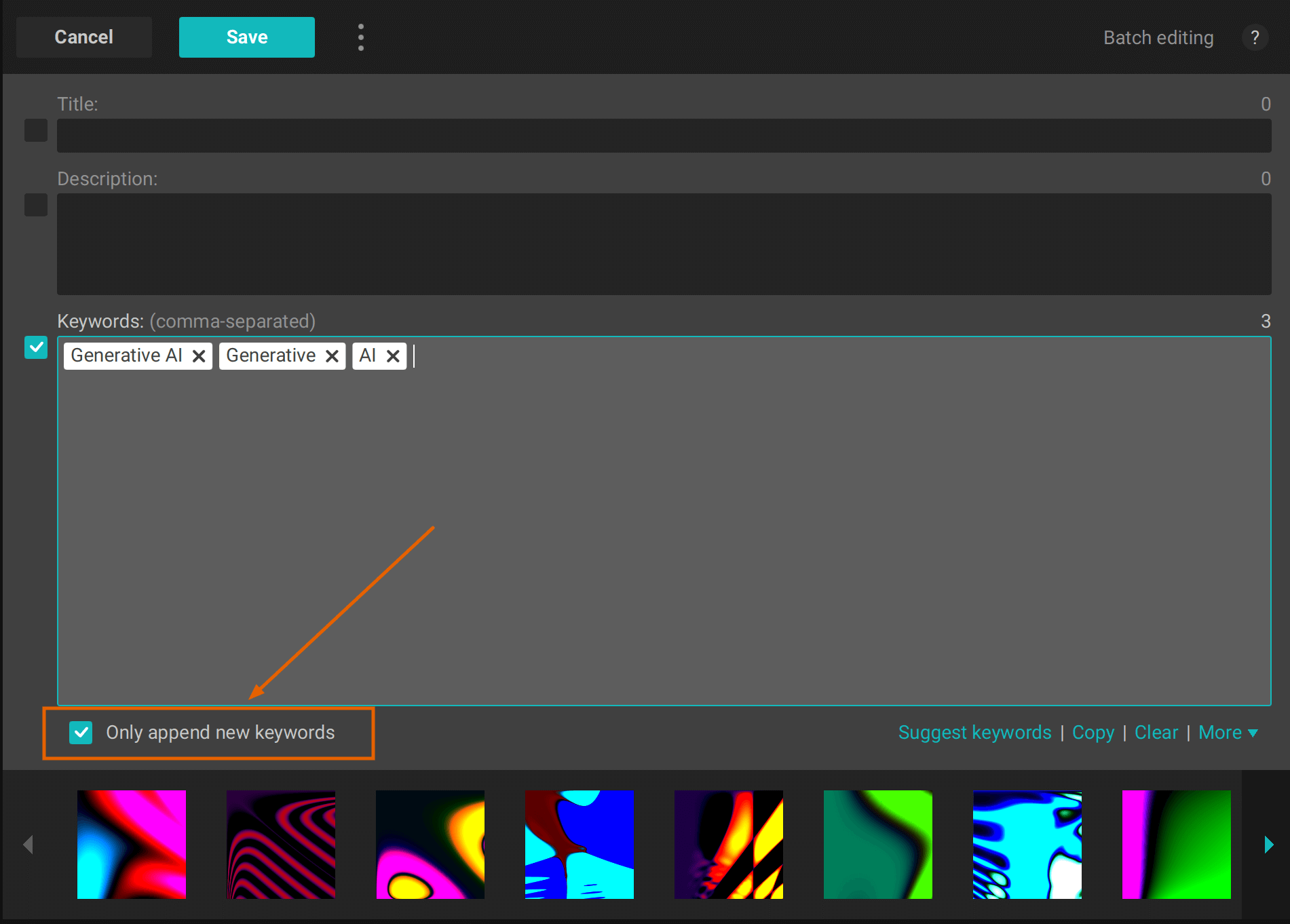
Appending correct keywords to existing artworks
If you added Descriptions and Keywords to artworks, but you forgot to add "Generative AI" set of keywords, you can do so in Xpiks by doing partial changes in the batch editing:
How much you can earn with AI-generated content
Except of obvious idea of uploading AI-generated content yourself, microstock agencies will compensate you when customers are using their AI generators and your artworks were used for its training. But this is not what I’d like to discuss.
The right question is not how much you can earn by uploading AI-generated content to microstocks. The question is how much generative AI can improve your work and, thus, make you earn more or work less.
Does “creativity block” sound familiar to you? This is a state of mind you reach when you’re exhausting your mental capacity for creativity. This is where generative AI can help: to get you going, to unblock you when you’re stuck, to offer different endings to your work or to complement your sketches. When was the last time you got a 40% productivity boost from using any tool the money can buy? Don’t rush to upload generated content, use generative AI to become a better artist instead.
Conclusion
Thank you for reading this far! Generative AI for images holds tremendous potential for transforming microstock industry, influencing both the agencies and the contributors. Instead of perceiving it as a threat, you can embrace it as a powerful tool that complements and enhances your creative process. By leveraging generative AI, you can not only explore new ideas but also become a more productive artist.
In the end, you will not be replaced by AI, but you will be replaced by people who use AI.



